分布式系统的数据复制和副本一致性
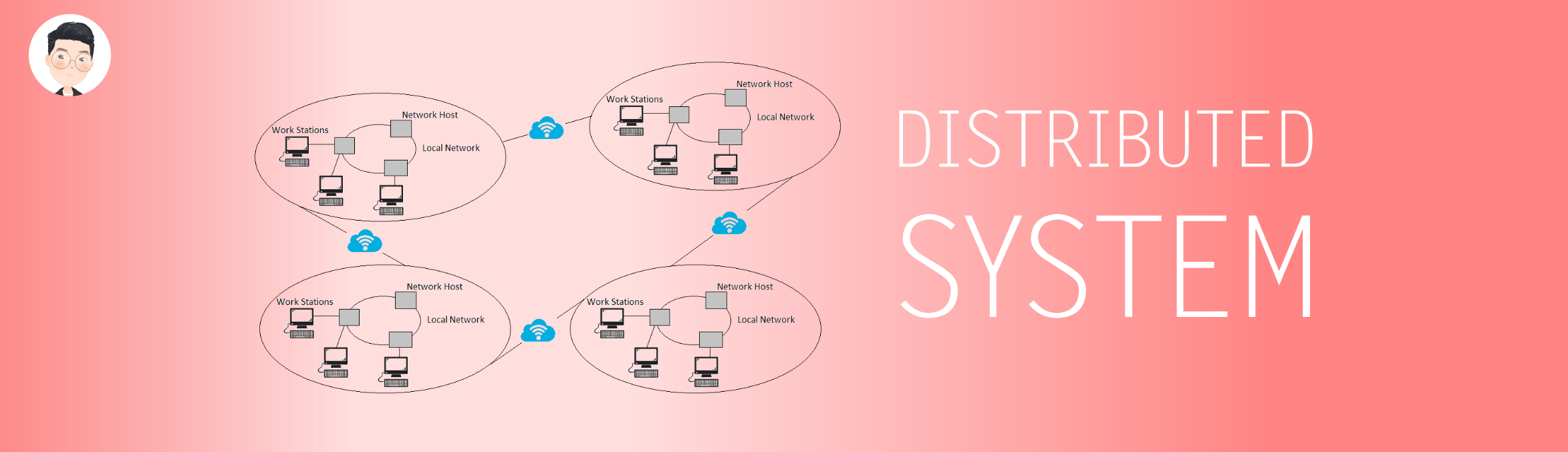
为什么需要数据复制
在分布式系统中进行数据复制,一般有以下三种目的:
- 使数据在地理位置上更接近用户,从而降低访问延迟(缓存)
- 当部分组件出现故障,系统依然可以继续工作,从而提高可用性(备份)
- 扩展至多台机器以同时提供数据访问服务,从而提高读吞吐量(分流)
数据复制的三种模型
主从复制
主节点与从节点
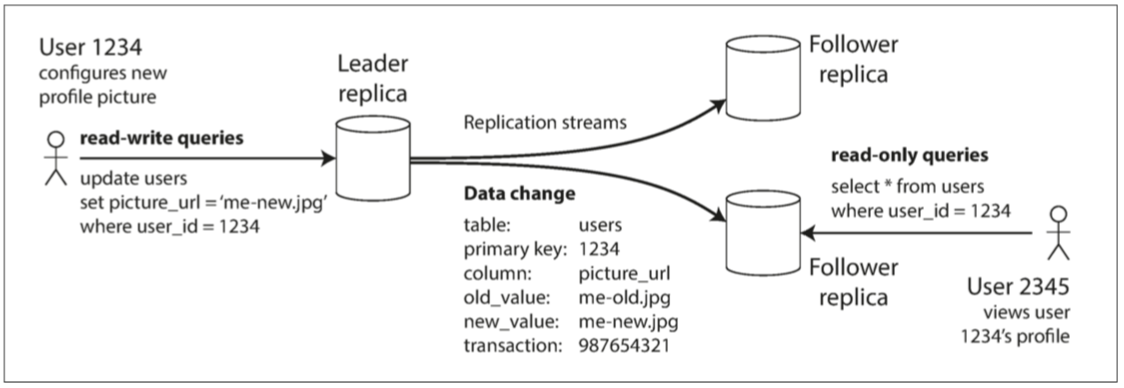
读请求可以由所有节点处理,写请求仅能由主节点处理并应用到从节点。
同步复制与异步复制
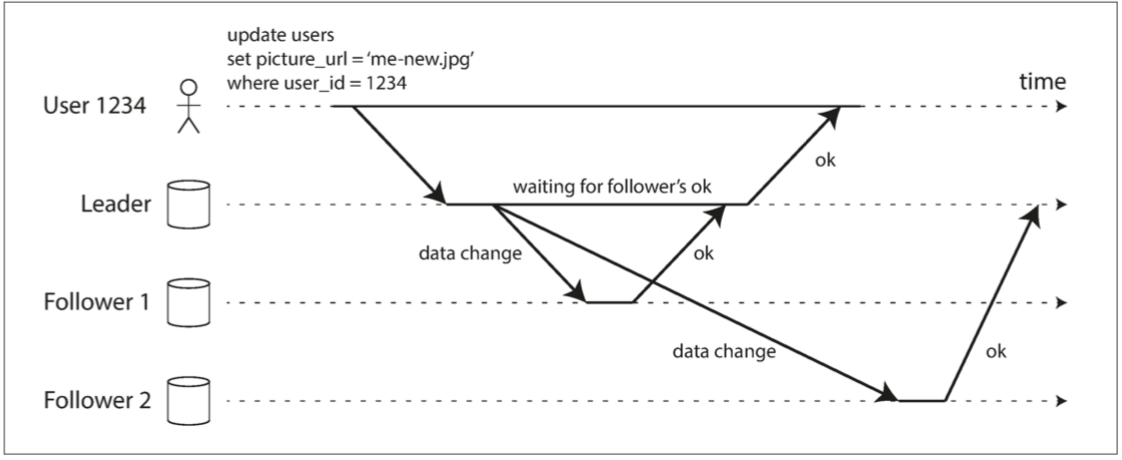
- 同步复制(Follower 1):主节点等待从节点确认完成后才能返回
- 异步复制(Follower 2):主节点发送请求后立即返回
同步复制的优点是一旦用户收到完成信息,用户就可以放心地认为所有其他用户查询到的数据都已经是最新版本。但与此同时带来的是网络延迟带来的低效率,以及因各种故障而阻塞的风险。因此大面积使用同步复制是不切实际的。
异步复制不会被阻塞,但即使用户已经收到了写入成功的信息,其他用户依然有可能看到旧版本数据。但是,在一段时间后,我们查询到最新版本数据的概率很高。理想状态下,经过较长的一段时间后所有人都会查询到最新版本。这种弱化的一致性保证叫做最终一致性保证。
实践中一般应用普遍异步复制与局部同步复制相结合的方法,以同时发挥二者的优势。
故障恢复
主节点失效
当整个系统开始运转时,我们可以人工指定一个节点作为主节点。同理,当原先的主节点失效时,我们依然可以人工切换主节点。
这个过程也可以自动进行,通过选举的方式。Paxos、Raft 等共识算法可以支持这种操作。
从节点失效
由于主节点以日志的形式向从节点增量式地分发数据更改,可以为每一个日志项都进行编号,从节点失效一段时间并修复后进行追赶式恢复,从主节点获得复制日志,并在比对本地编号后将复制日志中本地未应用的一切更改依序应用。随后就可以和其他节点一样正常工作。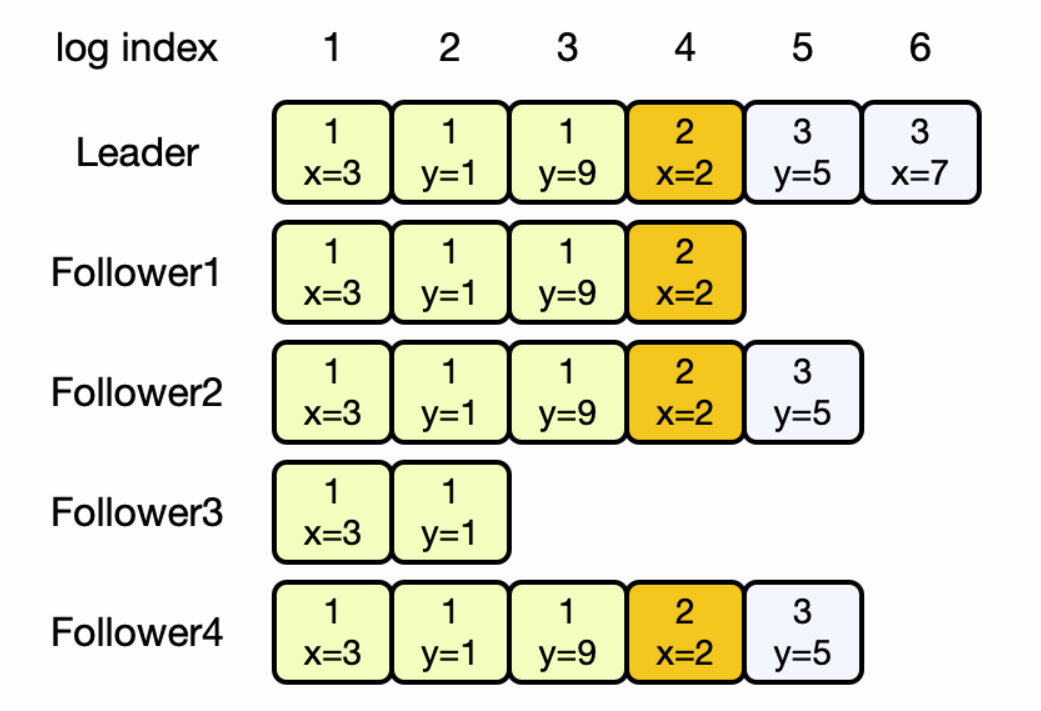
系统扩展
若由于种种原因,系统在运行了一段时间后有新的节点加入,从头开始进行增量式的追赶式恢复是极其低效的,很多时候甚至根本无法完成。这时采用快照+日志结合的方式进行恢复:首先请求主节点在某个时刻保存的快照,随后基于此快照的版本,进行追赶式恢复应用后续内容。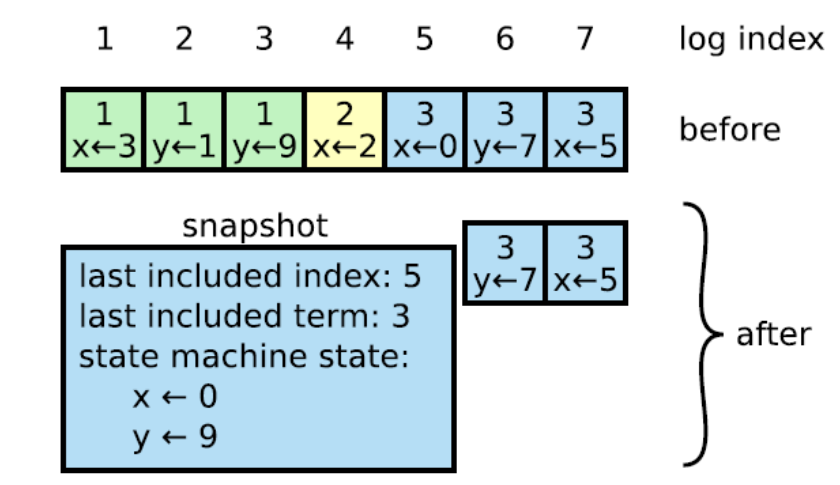
实现更强的一致性保证
异步复制只能提供最终一致性保证,这样的保证往往足够合理,但也可能在一些情况下难以满足需求。
写后读
考虑这样的情况:我们修改了自己的头像,但网页刷新后却没有看到头像发生变化;或者我们在一个帖子下评论了一些内容,但随后不久再次进入时却没有看到自己先前的评论。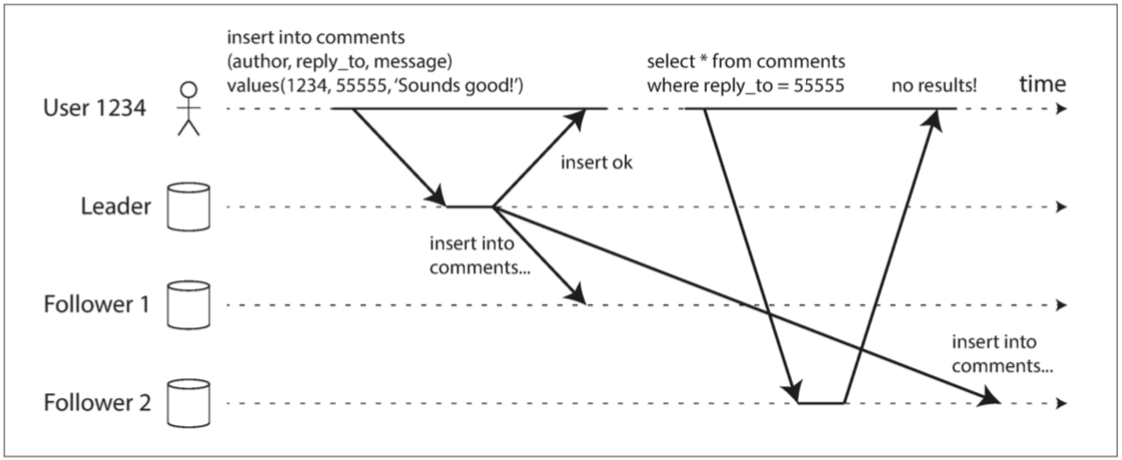
如何解决这样的问题呢?解决方法有很多,以下列举几种有一定合理性的思路:
- 对于容易被用户修改的信息(譬如用户的个人信息)的读取请求,一概路由到主节点
- 客户端记住自己最近写入请求的时间戳,并在随后的查询请求中附上,只有数据版本不早于该版本的从节点才能响应该请求
- 服务端记录被请求内容最近更新时间,若在前不久刚被更新,则将请求路由到主节点
重复读
若用户从不同副本先后多次读取同样的内容,则有可能出现所读取的数据向后回滚的情况。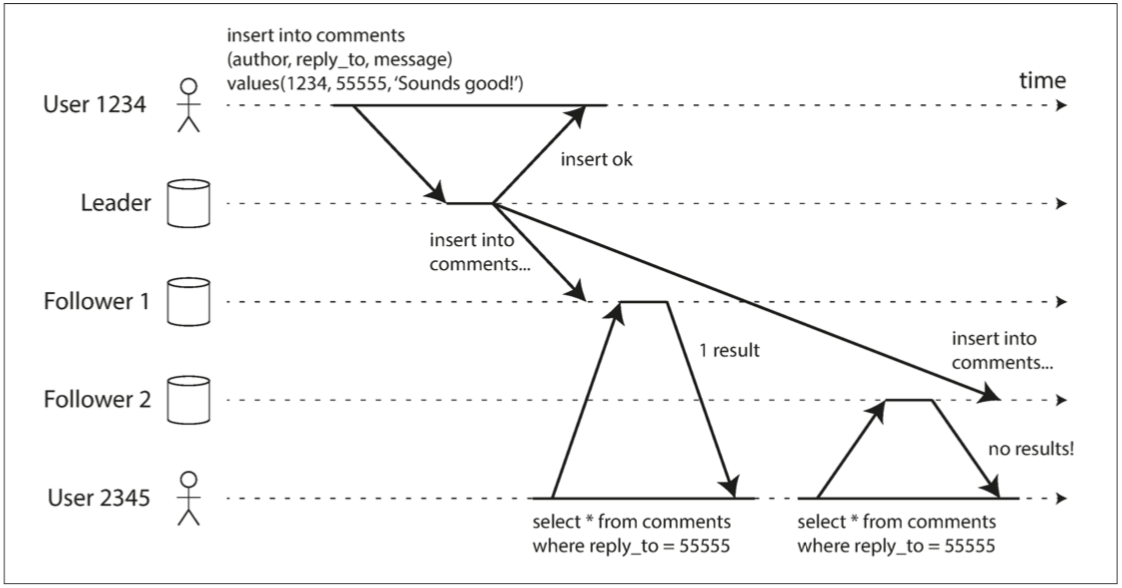
解决这个问题的其中一个方法是将同一用户对同一内容的请求始终路由到相同的从节点。这个方法可以通过对用户 ID 进行 Hash 来实现。
多主节点复制
引入多个主节点
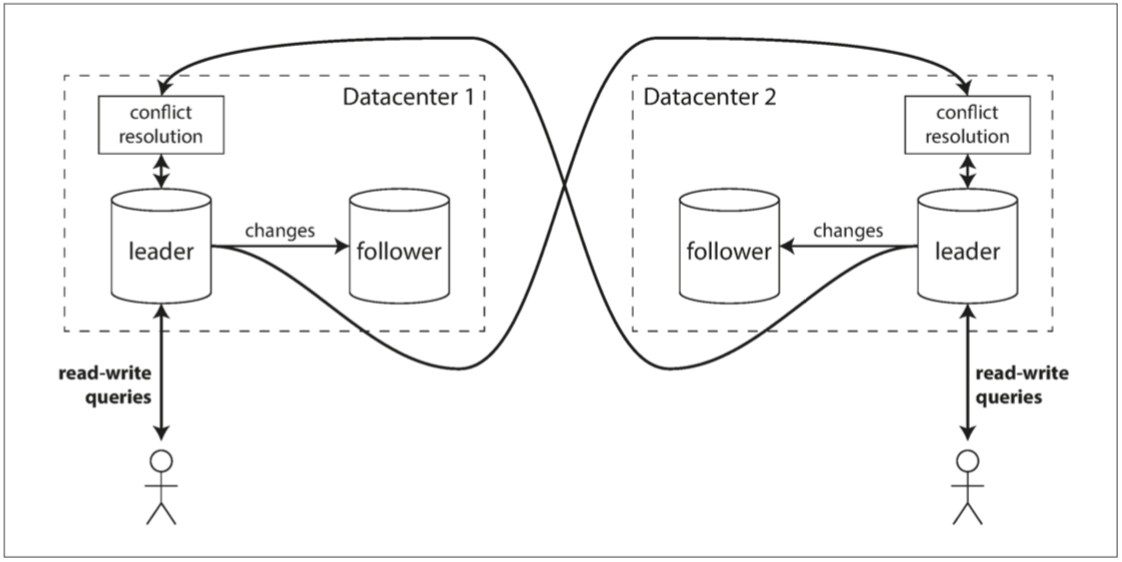
在多主节点系统中,有多个主节点,其中每一个都可以单独处理写入请求,并将数据变化通知它的从节点以及其他的主节点。这样做的理由有很多。
- 在跨区域的大规模分布式系统中,若所有的写请求都需要由部署在某地的唯一的主节点来处理,则将会产生严重的问题(主节点负载过大、网络延迟过高等),难以发挥分布式系统的优势。多主节点系统则没有这样的问题。
- 若数据中心之间的网络发生故障,每个具有主节点的单个数据中心都可以独立于其他数据中心单独提供服务,并在网络恢复后进行同步。
- 若本地应用希望实现离线状态下依然可以进行读写(并在联网后同步),就需要有一个能够充当主节点的本地数据库。可允许多个主节点同时存在的多主节点系统可以很好地支持此类需求。
冲突处理
多主复制在引入多个主节点的同时,也引入了潜在的写冲突。如果是主从复制系统,则两个同时进行的写入操作将有一个被阻塞直至另一个完成。但多主系统将不会阻塞两个操作的任何一个,除非它们是由同一个主节点处理,这就引入了数据冲突。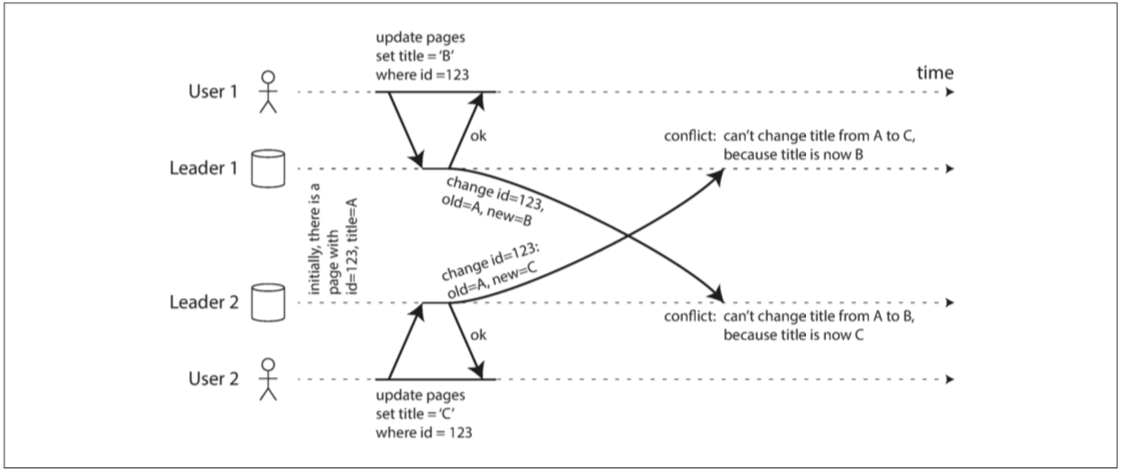
可选的应对策略包括但不限于:
- 使对于特定数据的写入操作都由同一个主节点来处理,从而直接防止冲突的发生
- 为每个写入请求分配一个唯一的 ID(时间戳、随机数等),在发生数据冲突时以最高 ID 的写入为准
- 为每个主节点分配一个唯一的 ID,在发生数据冲突时以最高 ID 的主节点为准
- 同时生效所有的冲突值,在用户查询时可以同时看到并列的多个值
- 直接通知管理员进行裁决
无主节点复制
去中心化的新思路
在无主节点系统中没有主、从节点的区别,所有节点都可以直接接受读写请求。用户读取数据时,在读取到的所有数据中选择其中的最新版本数据作为结果。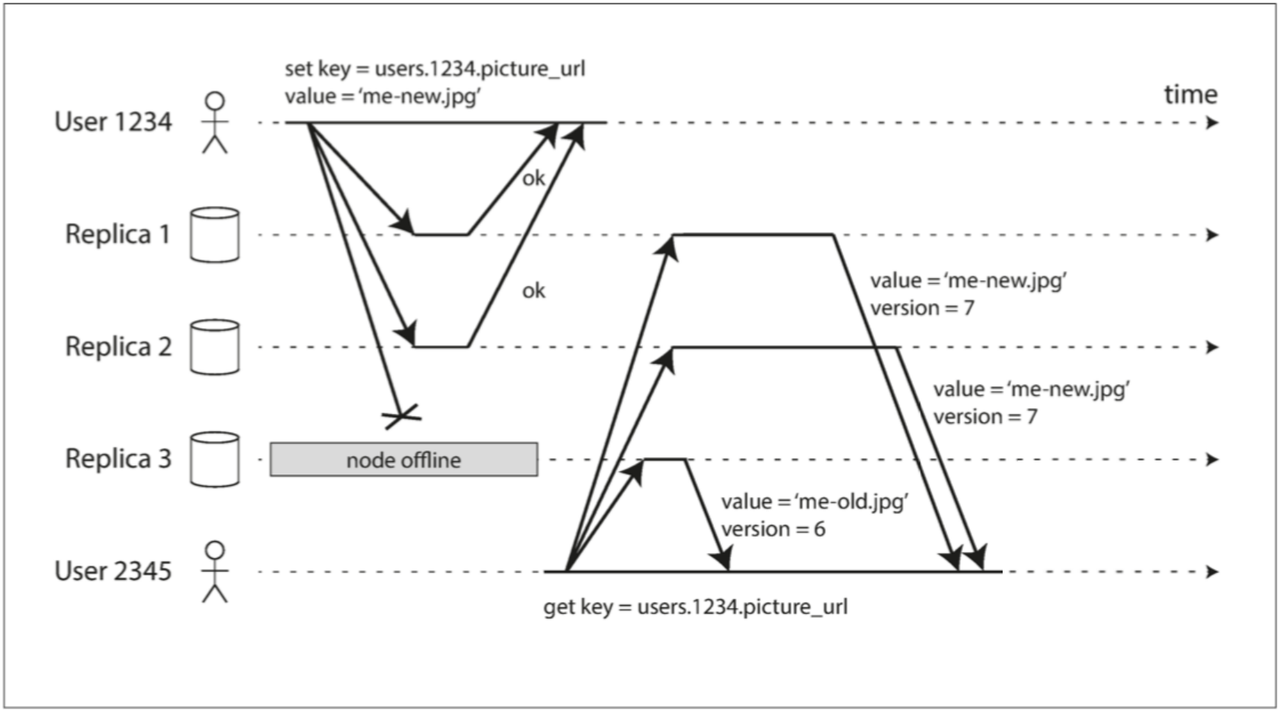
法定票数机制
为了使得所有节点的数据满足一致性约束的同时尽可能保证读取和写入的高效进行,我们需要引入一个法定票数(quorum)机制。
假设有 n 个节点,只要成功写入其中的 w 个节点即可认为写入成功,只要成功读取其中的 r 个节点即可认为读取成功。显然,除极个别情况,只要满足 w + r > n 的条件,任何一次成功读取都将读取到至少一个最新值。根据不同负载可以选择不同的 w 和 r 的值,一般情况下取 w = r = ceil((n + 1) / 2),若读取远多于写入,采取 w = n, r = 1 的策略能够大大提升均摊效率(但严重降低了容错能力,任何一个节点的崩溃或网络故障都会使系统完全失去写入功能)。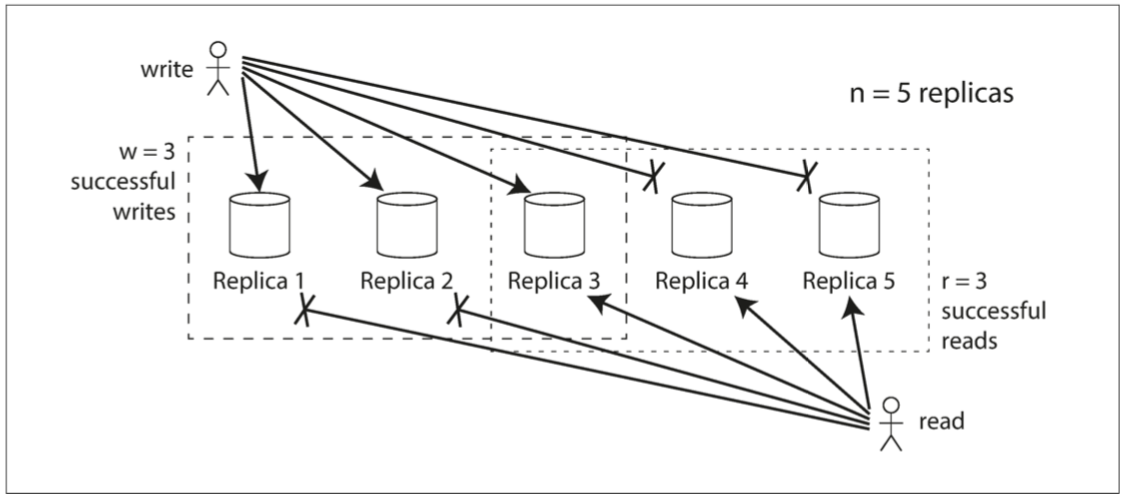
有时,为了提高性能和容错能力,也可以采取 w + r <= n,虽然会在一定程度上牺牲一致性。
故障恢复
若某个节点离线一段时间后恢复,或因网络原因部分节点未能接收到刚刚写入的最新值,这时需要采取措施进行数据同步。在无法借助主节点帮助的情况下,典型的无主节点系统通常使用以下两种方法:
- 读修复:当客户端获得来自不同副本的多个查询结果并采纳最新版本后,可以对未被采纳的数据源进行校正操作。使用这种方法时,可能会有一些副本因访问频率低而长期处于版本落后状态。
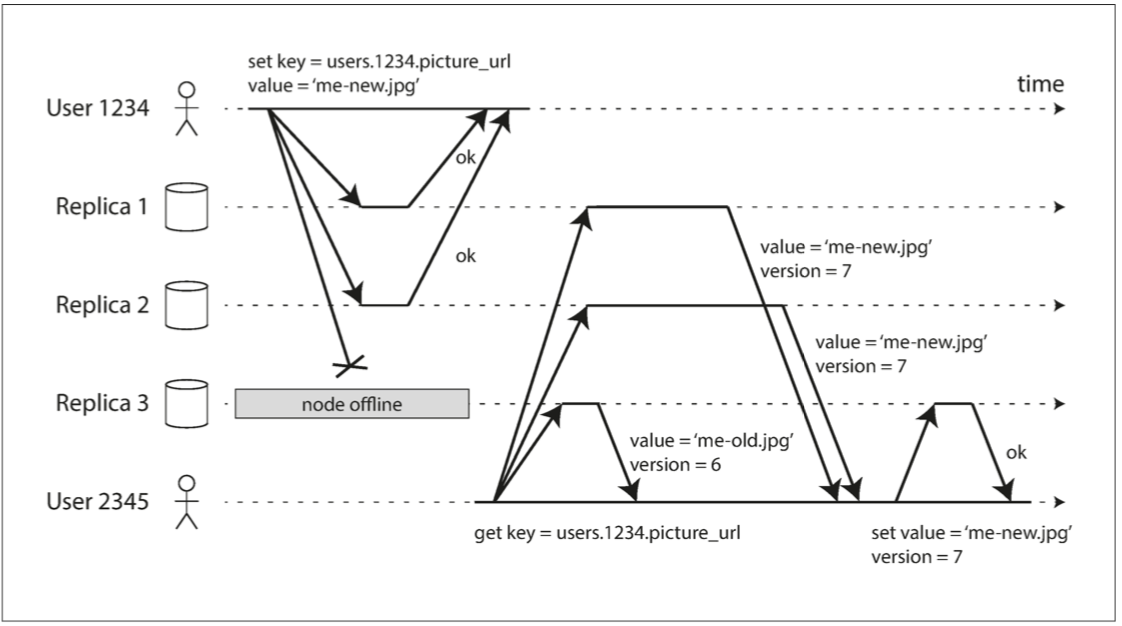
- 反熵:可以运行一个恢复节点,以固定频率不断查找副本之间的数据差异,并协助更新落后的副本。
冲突处理
和多主节点系统类似,无主节点系统在面对并发写入(甚至非并发写入)时也会产生数据冲突的问题。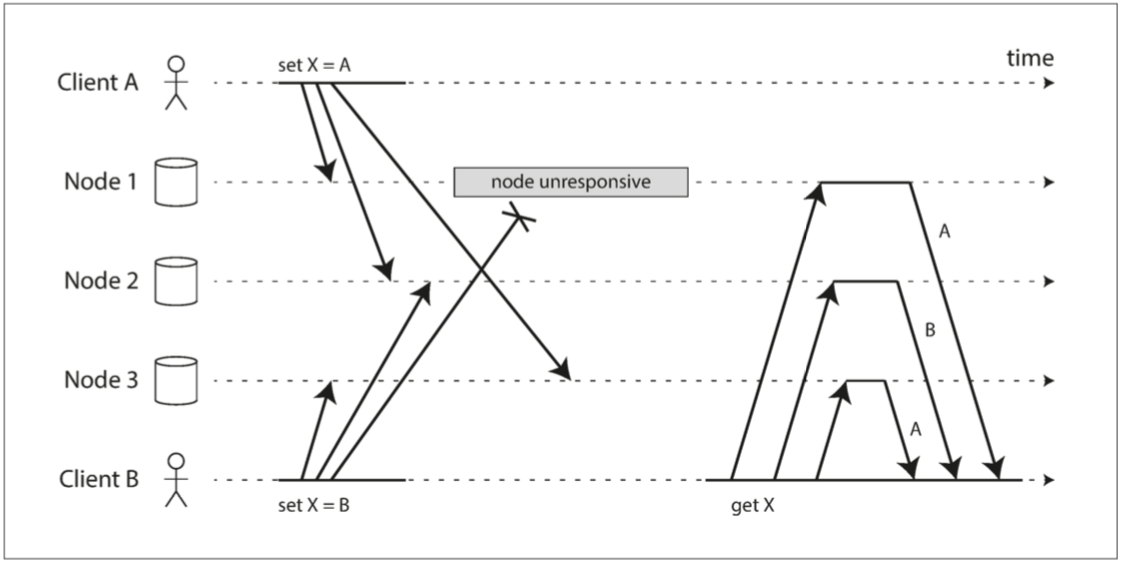
这个问题的解决方法包括但不限于:
- 最后写入者获胜:对互相独立的两个写入进行强行排序,要求每个节点只保留整个系统所有冲突值中的最新值,丢弃其他的值(会造成并发写入值中除被采用值的其他值丢失)。如何判定哪个值是最新的?可以为写请求附加时间戳。
- 合并同时写入的值,在查询时全部返回。比如,两个人同时向同一个账户的购物车中添加不同的商品,那么理想的选择可能是同时保留这两件商品。
- 也可通过推测写入请求的因果关系进行抉择,灵活应用上面的两种策略。对于明显具有先后因果的两个写入(即不具备并发性)可以放心地以最新版本为准;否则,对于真正的并发写入情况,很多时候适合使它们同时生效。